





Intro
The question, “How do robots work?” is one that I get from friends, family members, etc. Usually, it’s prefaced by some version of “I saw this video on YouTube…”. It’s a good question. Since the release of ChatGPT in 2022 the number of Google searches for the term “AI” has skyrocketed. Nvidia (the company that designs the GPUs which are used for much of this AI research) has grown so much that it recently replaced Intel in the Dow Jones Industrial Average. Artificial Intelligence is on a lot of people’s minds.
I’ve noticed that there’s a lot of confusion and concern about what current AI tools (including robots) are actually capable of. Marketing videos featuring humanoid robots show seemingly human levels of intelligence and skill, like this video from Figure or this video from Tesla.
I love cool robot demos. Boston Dynamics videos like this one of robot’s dancing or this one of Atlas doing parkour are what inspired me to get a Ph.D. in robotics. But do these videos really show the true capabilities (and limitations) of robot systems? A great example is this video of a new humanoid robot named Neo. The video makes it seem like Neo will be able to do all your household chores but in reality, when the WSJ tested Neo, a human was remotely controlling it the whole time.
So how do these robots really work? Will they take over our lives and our jobs soon? My goal is to help answer the first question so that you can answer the second question.
What is the Goal of Robotics?
The goal of robotics is to create intelligent systems that interact with their environment to change the state of the world. Contrary to popular belief this does NOT mean creating fully autonomous systems. Rather, it means creating systems that are able to successfully perform specified tasks with a high degree of autonomy.
This is an important distinction to make. I’m sure there are some researchers who would like to create “true” artificial intelligence but the market for that isn’t great. No one wants to pay for a robot that decides to lounge around, ignore you, and not do the dishes when you ask. There are already plenty of teenagers who will do that for free. What most researchers and companies are really working towards is systems that can accomplish specified tasks like writing your history essay or doing your chores for you.
What is a Robot?
A robot needs two things
- A body which they can use to interact with the world (usually some sort of frame with motors attached to it) and
- A brain that they can use to reason about what actions to take (usually several levels of software running on a small computer).
Having both a body and a brain is crucial. ChatGPT is not a robot because it has no way to physically interact with the world. Neither is your average car, which lacks the ability to autonomously drive your kid to soccer practice. An example of a robot is the Waymo self-driving car. It has both embodiment AND intelligence. You order a Waymo car on Uber, tell it where to pick you up and drop you off, and it does the rest.

Not a Robot

Not a Robot

Robot
Robot Hardware
Robot hardware is impressive and that’s a big reason why robots seem to be so advanced. Having good, reliable hardware is a big part of having good demos. Companies like Unitree, Booster Robotics, Figure AI, Tesla, Boston Dynamics, and Agility have all created very impressive humanoid robot hardware. Some of the major challenges that exist in the hardware space still include power supply, onboard computer size, and hands.





It’s hard to pack enough battery power and compute resources into a small form factor. There are two options for doing lots of powerful computations and reasoning. The first option is the have powerful onboard computers and the second is to always be connected via the internet to a powerful computer somewhere else. ChatGPT (and other large language models) does the latter, the interface sends your request back to a large datacenter where all the computations happen and then sends the response back to your computer.
For robots, the doing the latter can be dangerous. Lag is annoying when you’re playing a video game or streaming a movie, but can cause real physical damage when, for example, your robot freezes mid step, making onboard computing a safer option. Running those computers takes energy that the motors need to move the robot so managing power budgets and computing resources are real challenges that hardware designers face.
Robot hands are also extremely difficult to design. Hands have lots of joints in a small space. This means we need to be pack lots of motors into a small space. It’s hard to design small, strong, reliable motors so many hands aren’t able to grasp with a lot of force and break frequently. Hands also need to be able to withstand your 100-200lb robot falling on them when it trips. For these reasons, many of the robots that you see above have nubs instead of hands.
Robot hardware is cool and is in a good place. There are still issues to be solved but I want to focus the rest of this discussion on how robot software works because that’s where a lot of the confusion seems to come from.
Robot Software
Programming a robot becomes more difficult as the environment becomes less structured. The more structured the environment, the easier it is to program the robot. Fig. (1) shows how we wish task difficulty would scale with lack of structure while Fig. (2) shows a more realistic idea of how task difficulty scales.
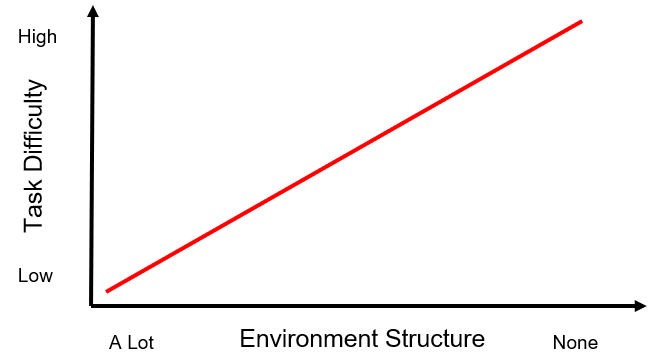
Fig. (1) How we would like to imagine task difficulty scales with removing structure from the environment.
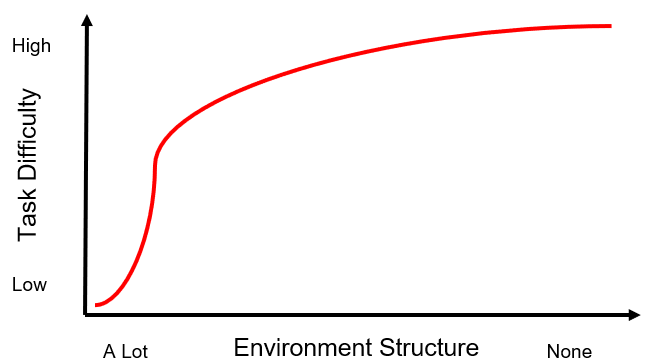
Fig. (2) How task difficulty scales really with removing structure from the environment.
As you can see in Fig. (2), things get difficult quickly.
But why does environment structure matter? It has to do with how we, as engineers, solve problems. Often, we try to solve complex problems in parts. We take a really big problem and break it into smaller pieces which we can solve individually. We then combined our solutions into something that solves the bigger problem. In order to isolate specific parts of the problem we make assumptions about the state of the world.
Structuring the environment is our way of trying to enforce the assumptions that we made on the real world. If any of our assumptions are violated, then we aren’t guaranteed that our solutions will work so we try to build an environment where our assumptions will always be true.
Where Robots Currently Operate
Robots have been used with huge success in highly structured environments manufacturing which we’ll define with the green shaded region in Fig. (3).
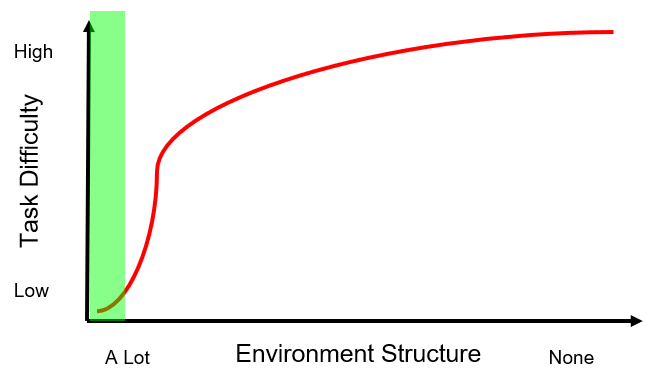
Fig. (3) Where robots have been deployed with high success so far.
These robots are great, they boost productivity and perform repetitive, dangerous tasks that would be difficult for humans to do. For the most part no one wants/is able to do the jobs that these robots are doing so they don’t really impact our workforce in a negative way. If anything, they increase productivity which increases profits which in turn increases the hiring capacity of the company and drives economic growth.
For manufacturing robots, we generally make the following assumptions about the world:
- We assume we know the size, shape, and location of obstacles.
- We assume that we know where we want the robot to be at specific times, what objects we want it to interact with, and how we want it to interact with those objects.
- We assume that our robots are bolted to the table.
- Finally, soft robots are hard to deal with so let’s assume that our robots have rigid skeletons.
This environment looks like robots inside cages doing repeatable, choreographed tasks on assembly lines. If we make all of those assumptions, then the big problem that we need to solve is motion planning (i.e. move from pose A to pose B without smashing into anything).




Motion Planning
Making all of these assumptions isn’t a perfect solution, but it at least gives us a place to start attacking the problem. There are many solutions to motion planning that are highly optimized and easy to implement. Two great examples are MoveIt and CuRobo. These software libraries use graph-based algorithms to plan collision free trajectories from the robot’s current pose to a specified goal pose (a pose is a position and an orientation and is how we define where the robot is in space). There is definitely still a lot of active research being done in this area, but the off the shelf tools are pretty good and this problem is largely solved.

Where Robots Are Starting to Operate
Commercial robots are starting to be deployed in less structured environments shown by the shaded orange region in Fig. (4).
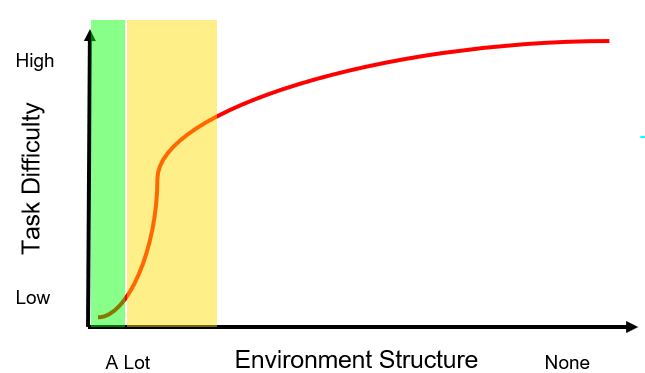
Fig. (4) Where robots are starting to be deployed.
To bring robots out of structured factory environments and deploy them in unstructured, dynamic environments, we relax some of the assumptions that we made earlier, develop some new tools, and combined them with the tools we already have.
Relaxing Assumptions

Specifically, we’ll relax three of the four assumptions that we made earlier:
- Instead of predefined scenes and obstacles we’re going to try to sense our environment and detect objects and obstacles.
- Instead of pre-programming robot poses, we’ll use our new sensing and object detection tools to reason about the best ways to manipulate objects.
- Instead of only working with robots that are bolted to tables, we’ll work with robots that aren’t fixed to anything and instead move around their environment on wheels or legs.
We’ll keep the fourth assumption that we are working with rigid robots rather than soft, flexible robots however.
Relaxing these assumptions raises lots of new questions. Here’s a few of them:
- What should we use to collect information about the environment?
- What type of data structure should we use to store and reason over the information we collect?
- How do we identify objects in the environment?
- How do we attach semantic meaning to the objects we identify?
- How do we reason about manipulating those objects?
- How do we account for future consequences of our motions (e.g. if the robot jumps, it can’t change its trajectory while in the air)?
This is not an all-inclusive list but it gives an idea of the types of questions that robotics researchers think about and try to solve.
Sensing the Environment
A lot of work has been done on sensing and object representation. Sensing technologies include radar, lidar, GPS, depth cameras, and RGB cameras. A popular way to represent sensed environments and objects is using point clouds, which are like 3D images where each pixel not only has RGB values but also a 3D position in space assigned to it (e.g. the rabbit point cloud below which is a collection of points in 3D space).

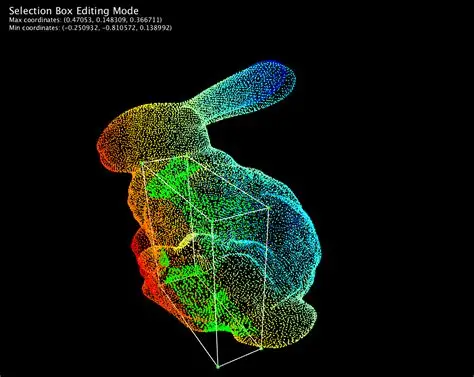
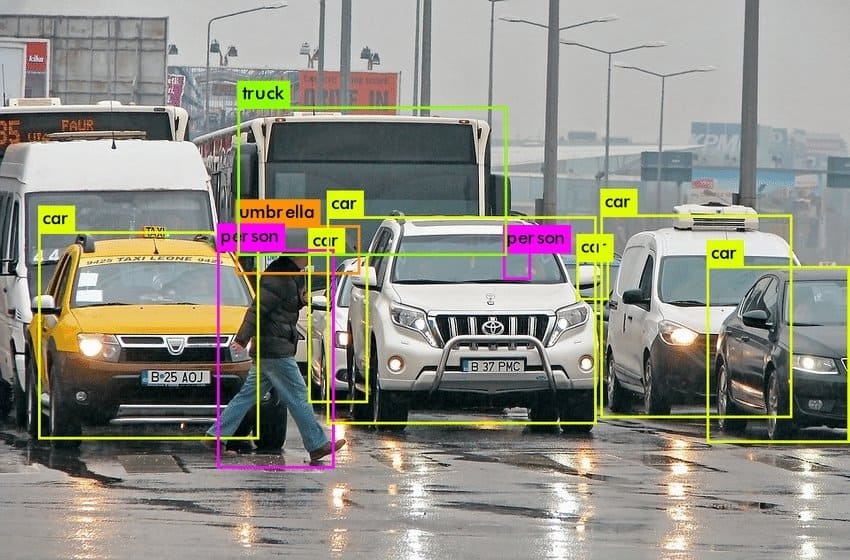
Object segmentation (identifying objects in the scene and then isolating them from the rest of the scene) was a major challenge until recently. In the past decade there have been several major breakthroughs that have led to machine learning models like YOLO (You Only Look Once) which take an image as input and return a list of objects detected in the scene, bounding boxes around those objects, and even segmentation masks (a segmentation mask is like the rotoscoping masks that VFX artists use to cut actors out of a green screen).
There are lots of object segmentation models now and they are awesome. There are some limitations still (inability to detect objects not in the training data, misclassified objects, etc.) but overall, the progress has been immense.
Another great tool for understanding the environment is SLAM (Simultaneous Localization and Mapping). As the robot moves through the environment it constructs a map by tracking where it has been and making connections between landmarks that it detects.
A good example of SLAM in action is the particle filter that the robot below uses to express its belief about where it is in that map. Each dot represents a place the robot thinks it might be. As the robot moves through the scene it encounters landmarks (doorways, flat stretches of wall, corners, etc.). It uses those landmarks to update its confidence about its location, moving dots away from areas that are very unlikely and putting those dots in areas that are much more likely.

SLAM algorithms have been around for a while now. There are still limitations (for example lidar is very precise but doesn’t work very well in the rain leading to errors and noisy data) but overall, the method is good enough to be rolled out on lots of robots including self-driving cars and robots in factories and warehouses.


Object Manipulation
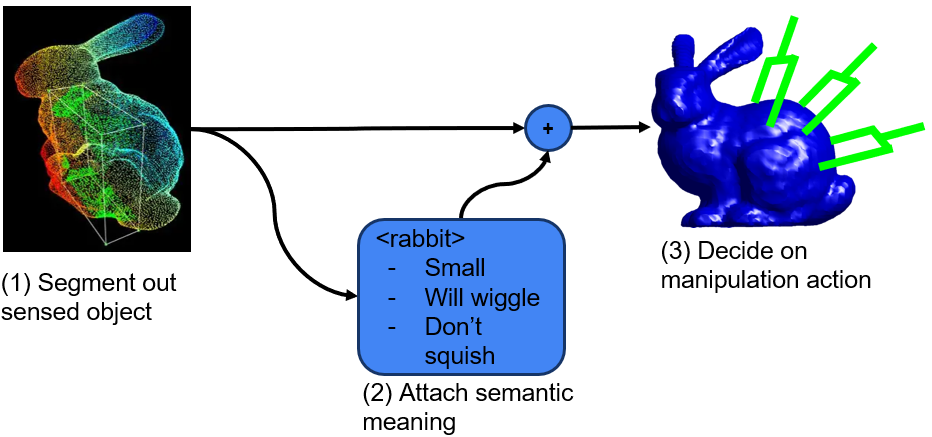
Manipulating an object requires some form of the following reasoning:
- The robot has to perceive the object. This means segmenting out the object’s point cloud from the scene (probably using a computer vision model like the ones we discussed earlier).
- Some semantic meaning has to be attached to the object. This semantic meaning includes information that the robot needs in order to reason about manipulating the object. This information can include object pose, material properties, things the object can be used for, etc.
- The robot then needs to combine both the segmented object representation and the semantic information and then generate an action to perform.
There are commercial robots that can do this kind of reasoning over objects but they generally only reason over two manipulation actions (pick vs. place) for a known set of objects (such as boxes in warehouse) and they use simplified grippers like parallel jaw grippers (think crab pincers) or suction cup grippers. A great example of this kind of robot is the Boston Dynamics Stretch robot which autonomously unloads cardboard boxes from shipping containers.

When it comes to more general manipulation with complex objects and complex multifigure grippers there have been some cool demonstrations using robots like the Boston Dynamics Atlas robot performing kitting tasks for car parts in an assembly line setting. This tech is still a long way from commercial deployment though and these demonstrations are a better example of the state of the art in research and development than an accurate representation of the capabilities of robust commercially available robots. In hand manipulation also presents a serious challenge. We take for granted our ability to grasp an object and then reposition it in our hands. Een simple skills like this are a major challenge for robot control software.

Motion Planning 2.0
As soon as we decide that our robots aren’t bolted to the table anymore, we enter the realm of underactuated robotics. Underactuated means that I no longer have the ability to apply acceleration to my system at every point in time. The best example I can give of a system that is underactuated is you! When you run or jump there are moments where you are airborne and unable to change your trajectory because your hands and feet have nothing to push off of. This means that you have to be really careful about how you plan your motions so that you don’t stumble or trip and fall. People who are really good at doing this motion planning (i.e. are really coordinated) generally become athletes. People who are less coordinated make robots.
Planning motions and safely controlling underactuated robots is a very active area of research. I’m going to highlight two approaches to control and their respective challenges.
Analytical Methods
Analytical methods rely on really good physics models of the robot that are analytically derived. This just means that someone sat down and thought really hard about how to describe the physics of the robot in terms of math and then took some measurements and wrote it all down. They also thought about what costs (e.g. don’t use a lot of motor torque) and constraints (e.g. no collisions) they could apply to the system and wrote those down as math.
The robot software plans motions by generating an initial guess about a trajectory that will reach the goal then iteratively refining that trajectory so that all the costs are minimized and the constraints are satisfied. Once the trajectory is optimized the robot executes the first step in that trajectory. But in executing that step the world might have changed so the robot throws out the rest of the trajectory and starts the whole process over. It does this replanning for each time step. This requires the planners and optimizers to be really fast. This method generalizes well because the assumptions made in the physics model generally don’t change (gravity on earth is pretty constant, mass is pretty constant assuming nothing falls off the robot, etc.). Things break down when there are unmodeled dynamics, poor measurements, or the robot can’t compute and optimize new trajectories fast enough. When it works however, analytical approaches are very elegant and produce beautiful results.
Data-Driven Methods
The other approach is to collect a lot of data of the robot doing random things and optimize the control policy based on what worked well and what didn’t work well. Since robots are expensive, this is usually done in simulated environments with simulated robots.

There are a couple of major challenges, however. One challenge what we call the sim-to-real gap. As much as we try, our simulated environments don’t reflect the real world perfectly so a policy that works perfectly in the simulator might translate to mediocre or poor performance in the real world.
Another challenge is creating enough situations in training to represent all of the situations the robot will encounter in the real world. If you remember, we initialized our policy so that it produced random actions and then optimized it to produce good actions in the states that it saw in the simulator.
The downside of this is that our policy generally produces random actions for states it hasn’t seen before (especially states that are wildly different from everything seen in training). The robot isn’t self-aware the way that we are, any reasoning it has about the consequences of its actions is embedded in these control policies, so the control policy thinks it’s doing great, producing optimal actions and all, right up until the point where someone turns the robot off because it’s dangerously thrashing about.

Completely Unstructured Environments - The Final Frontier
Now we understand a bit more about how robots work, what assumptions we have to make to get them to work, and where the state of the art is in terms of control, perception, and motion planning. So why are tech companies making big promises about robots that will operate in completely unstructured environments (see Fig. (5)) like your home?
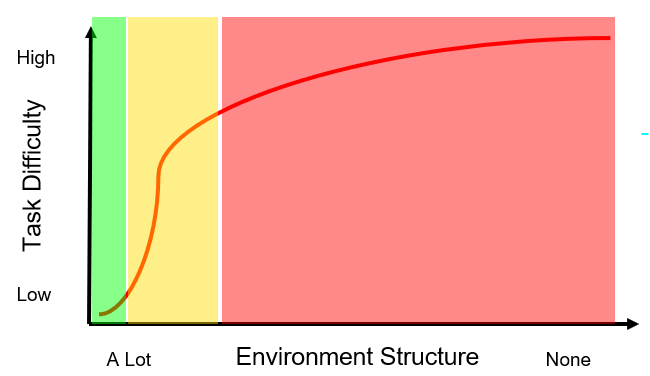
Fig. (5) Where many tech companies are saying their robots will be able to operate.
The answer is this. At the beginning of the 2020’s there were two pivotal things that happened that changed computer science forever (this book does a great job presenting them). The first was that internet connection between devices became very fast, like fast enough that accessing millions of images and text documents from anywhere in the world wasn’t a big deal anymore. The second was that computing power, and especially parallel computing power (see this video for an explanation about parallel computing vs. serial computing) reached a very high speeds.

Problems like machine translation (using a computer translate text from one language to another) and speech recognition have long interested computer scientists and a lot of machine learning theory has been around for decades. The intersection of internet scale data and fast parallel computing opened the door for an explosion of success in text and image generation. Suddenly it was possible to take the entire internet’s worth of text and image information and compress it into these neural networks. It was also possible to recover that information from the neural networks using unstructured queries.
Essentially means that large language models and image generation models are compresses databases with unstructured queries. There are some people that will argue that these models generate truly novel responses when prompted, but research and intuition suggest that this is not actually the case. Having seen pretty much everything that has ever been created by humans, these models don’t really need to generalize to produce interesting and useful results, they just need to memorize and the loss functions that we construct to represent what “good” outputs are during training often encourage memorizing.
What Does This Mean for Robotics?
One conclusion that many in robotics have drawn from the success of vision and language models is that big data equals big results. The thought is that if we can just collect enough demonstrations of robots doing things then we can create similar models for robots. This area of research is called learning from demonstrations (also behavior cloning or imitation learning). The goal is to learn policies that take images and text as input and generate robot actions as outputs. This is the same basic idea as the data-driven motion planning approach that we discussed earlier.

What this ends up looking like is hundreds of people in mock factory environments providing “expert” (i.e. human) demonstrations of tasks. Often these demonstrators remotely control robot doing the task. Cameras and sensors measure and record everything that happens from the robot’s perspective and then that data is used to train policies that, given the same images, joint position measurements, etc. produce similar actions to the ones the demonstrator did during data collection. Learning from demonstrations can produce really awesome results like in the videos below which are from recent work by the Toyota Research Institute.
There are still many drawbacks to this approach however. For example, there isn’t any conclusive evidence that these models actually reason or understand the tasks that they are doing. In fact, there is a lot of evidence that points to the contrary. Many of these models are brittle to changes in the environment, with performance dropping sharply when things like the color of the object or the lighting of the room are changed. This does not suggest generalization, but rather memorization. Given the evidence that language and image models are memorizing, rather than generalizing, intuition suggests that these robot models (which use similar training techniques and model architectures) are doing the same thing. Another major issue is that when the robot is in unseen states, the policy may produce random actions. This can be dangerous, especially if the robot is holding a tool like a wrench or a knife. There are also some pretty influential voices in the computer science world who think that models that map only text and images to robot actions don’t provide robots with enough understanding about the environment and the consequences of their actions.
Bonus Content: The Economics of Commercial Robotics
This last point I want to make is not so much about how robots work but about how the economics of robotics work. Last summer I conducted about 20 informational interviews with employees at various robotics companies including humanoid robotics companies, industrial robotics companies, and self-driving vehicle companies. I observed that most of these companies have concepts of a product but nothing that generates revenue. Many of these companies are venture backed and are riding on the coat tails of the larger AI bubble that’s happening right now. This Forbes article discusses major investments different tech companies and the government have made in AI the last year. If you read through the list then you’ll start to see a lot of the same names appearing as both lenders and borrowers. It’s a little bit like this Three Stooges sketch.
This circular pattern of investments is great if there are products that are generating revenue, but even companies like OpenAI (which have the most marketable versions of a product) have huge losses. The companies that are making money right now are the ones selling computing services but there are physical limits to how fast this computing infrastructure can be built out and already some of these proposed projects are falling behind schedule. It’s still early days for this technology so a lot could happen. Essentially AI is the hot new tech and robotics companies are going to keep spending and developing while the bubble lasts and see how far they can get.
In Conclusion
As promised, I’ve given you the answer to the first question, “How do robots work?” You’re now an expert on the high-level state of the art! There are a lot of cool things that we can do with robots but there are also a lot of things that we can’t do well yet. What do you think the answer is to the second question? Will robot’s take over soon? Now that you’re an expert you can make your own assessment of what’s really going on behind the scenes when your friend shows you a cool robot video. Thanks for reading and please share your thoughts about when the robot takeover will happen!